In this chapter, we will extend the concept of the linear model to include the case where we want to predict categorical outcomes on the left-hand side of our model equation. In order to do this, we will have to learn an extension of the OLS regression model called the generalized linear model which will provide a more flexible way to specify linear models, including ones with categorical outcomes. By the end of this chapter, you will be able to run full linear models with dichotomous (two categories) and polytomous (many categories) variables as outcomes.
Dichotomous Outcomes and The Binomial Distribution
We now have a great many tools to produce more complex and realistic specifications for the right-hand side of the linear model formula. We can add dummy variables, interaction terms, transformations, splines, and polynomial terms. For outcomes, however, we are still stuck with quantitative variables, which eliminates a lot of potential outcomes that we care about in the social sciences.
Lets take the Titanic data as an example. The obvious outcome of interest is whether someone survived or died on the Titanic. We already know how to examine a bivariate relationship between survival and one other variable. We can do this using a two-way table if the other variable is categorical and mean differences if both variables are quantitative. However, we can’t put this into a model framework where we can control for multiple variables simultaneously, look at interaction terms, model non-linearity, etc.
For example, we know that women were more likely to survive the Titanic than men and we know that higher-class passengers were more likely to survive than lower-class passengers. However, we also know that women were more likely to be higher-class passengers than men. How much of the gender difference in survival might be accounted for by these underlying class differences? Alternatively, we might be interested in interacting gender and passenger class to look at how the gender difference in survival varies by passenger class. Both of these tasks would be easier if we could use the same model framework we have developed to predict survival and death.
It turns out that we can use this model framework, but in order to do so we need to develop more understanding of the data-generating process that underlies the survivals and deaths on the Titanic, and by extension any dichotomous outcome in which there is a choice between two categorical possibilities. It turns out that this data-generating process is the binomial distribution.
The binomial distribution
The binomial distribution is a theoretical probability distribution that arises when we have some process that follows these rules:
We perform \(n\) repeated independent trials where the result of each trial is either a success or failure. The language of “success”” and “failure”” here is purely aesthetic. We can use the binomial distribution in any case where there are two possible outcomes.
The probability of success on each trial is given by \(p\). Because there are only two possible outcomes, the probability of a failure must therefore be \(1-p\).
The binomial distribution governs how many successes we can expect to see in these \(n\) trials. We consider that number of successes to be a random variable and traditionally write it as \(X\).
One of the simplest example of a binomial distribution would be to count the number of heads in a certain number of coin tosses. In this case, \(p=0.5\). However that example is boring so instead we will consider the basic dice mechanic from the popular Shadowrun tabletop role-playing game. In that game, players determine whether their characters succeed at a task by rolling a “dice pool” which is a certain number of six-sided die. They then count the number of 5’s or 6’s that they roll on this dice. This count then determines whether they succeed and by how much. On an evenly-weighted die, the probability of rolling 5 or 6 should be two out of six, which simplifies to one out of three, so we have a binomial distribution with \(n\) equal to how many dice the character has in their pool and \(p=1/3\).
The binomial distribution formula below will tell us the probability that \(X\) equals some number of successes \(k\):
\[P(X=k)={n \choose k}p^k(1-p)^{n-k}\]
This formula may look complex, but its actually fairly intuitive if we break down into its parts. The binomial formula basically has two parts:
\(p^k(1-p)^{n-k}\) defines the probability of getting any particular sequence of \(k\) successes and \(n-k\) failures.
\({n \choose k}\) tells us the number of unique ways that we can combine \(k\) successes and \(n-k\) into a sequence.
Lets start with the first part. Lets assume that our Shadowrun player had a dice pool of five dice, so \(n=5\). What is the probability that they rolled the following sequence: success, success, failure, failure, failure?
One important feature of probabilities is that when events are independent, then the probability that they all happen is given by multiplying the individual probabilities together. In this case, the probability of a success is \(1/3\) and the probability of a failure is \(2/3\). Therefore the probability of getting that exact sequence is given by:
I just multiply the probabilities together to get the probability of the exact sequence. Because I am multiplying the same number together, I can collect these terms together by using powers. The probability of getting this exact sequence is 0.033 or 3.3%.
Note that this is also the probability of getting the sequence of success, failure, success, failure, failure because the order of the multiplication can be moved around and will still come out to \((1/3)^2(2/3)^3\). So, this is the probability of getting any particular sequence of two successes and three failures.
I can generalize this to any \(n\) and \(k\) by just replacing the numbers with the abstract values. So: \[p^k(1-p)^{n-k}\] is the probability of any particular sequence of \(k\) successes and \(n-k\) failures in \(n\) trials.
Notice that I keep saying “any particular sequence.” If we are only interested in the total number of successes, we don’t care what order they come in. However, the equation above, only gives us the probability of getting a particular order of \(k\) successes and \(n-k\) failures. To consider the total probability of \(k\) successes, we have to consider all the possible ways we could get a sequence giving us \(k\) successes.
For example, to continue our example of the Shadowrun dice pool of five dice, how many ways could we combine two successes and three failures. Here are all the ways:
SSFFF
SFSFF
SFFSF
SFFFS
FSSFF
FSFSF
FSFFS
FFSSF
FFSFS
FFFSS
There are ten possible sequences (or permutations) that would give us two successes in five trials. Each of these permutations has a probability of 0.033. To get the overall probability we need to add them up or just take \(10*0.033=0.33\). So, the actual probability of rolling two successes in five trials is about 33%. Thats much better than 3.3%! The lesson here is that permutations matter.
How can I determine the number of possible permutations systematically? Thats what the \({n \choose k}\) or “\(n\) choose \(k\)” formula answers. This formula is given by:
\[{n \choose k}=\frac{n!}{k!(n-k)!}\]
If you are wondering what all the exclamations points are about, its not because I am really excited (although I am). These are called factorials. A factorial indicates that a number should be multiplied by all of the descending integers down to one. So, \(4!\) is actually:
\[4*3*2*1\]
In practice, many of the numbers in the n choose k formula actually cancel out so it typically involves less math than you would think. Here is the n choose k formula for \(n=5\) and \(k=2\):
When we put these two parts together, we get the full binomial formula:
\[P(X=k)={n \choose k}p^k(1-p)^{n-k}\]
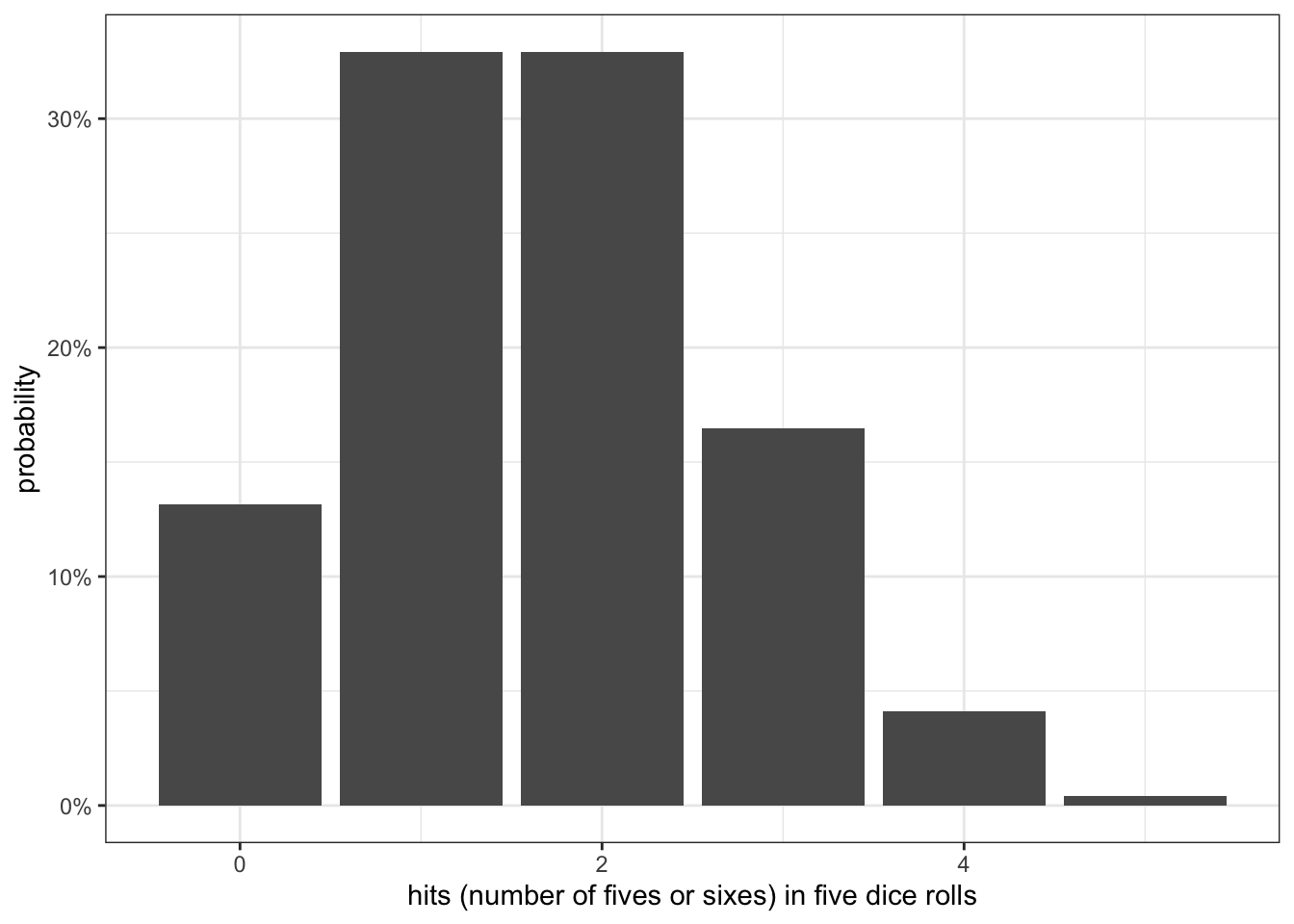
n <-5k <-0:np <-1/3prob <-choose(n,k)*p^k*(1-p)^(n-k)ggplot(tibble(k,prob), aes(x=k, y=prob))+geom_col()+scale_y_continuous(labels=scales::percent)+labs(x="hits (number of fives or sixes) in five dice rolls",y="probability")+theme_bw()
Figure 7.1: Probabilities of the number of hits (rolling a five or six) in a five dice pool
Figure 7.1 shows these probabilities for each possible value of \(k\) in a five dice pool (i.e. 0 through 5). We have about a one in three chance of rolling either one or two successes and about a 12% chance of getting no successes. At the other end of the spectrum, it is very unlikely to get five successes in five trials. Go ahead and pause here and play this game for yourself if you like to see how your results stack up. Al you need is five dice. Go ahead, I will wait.
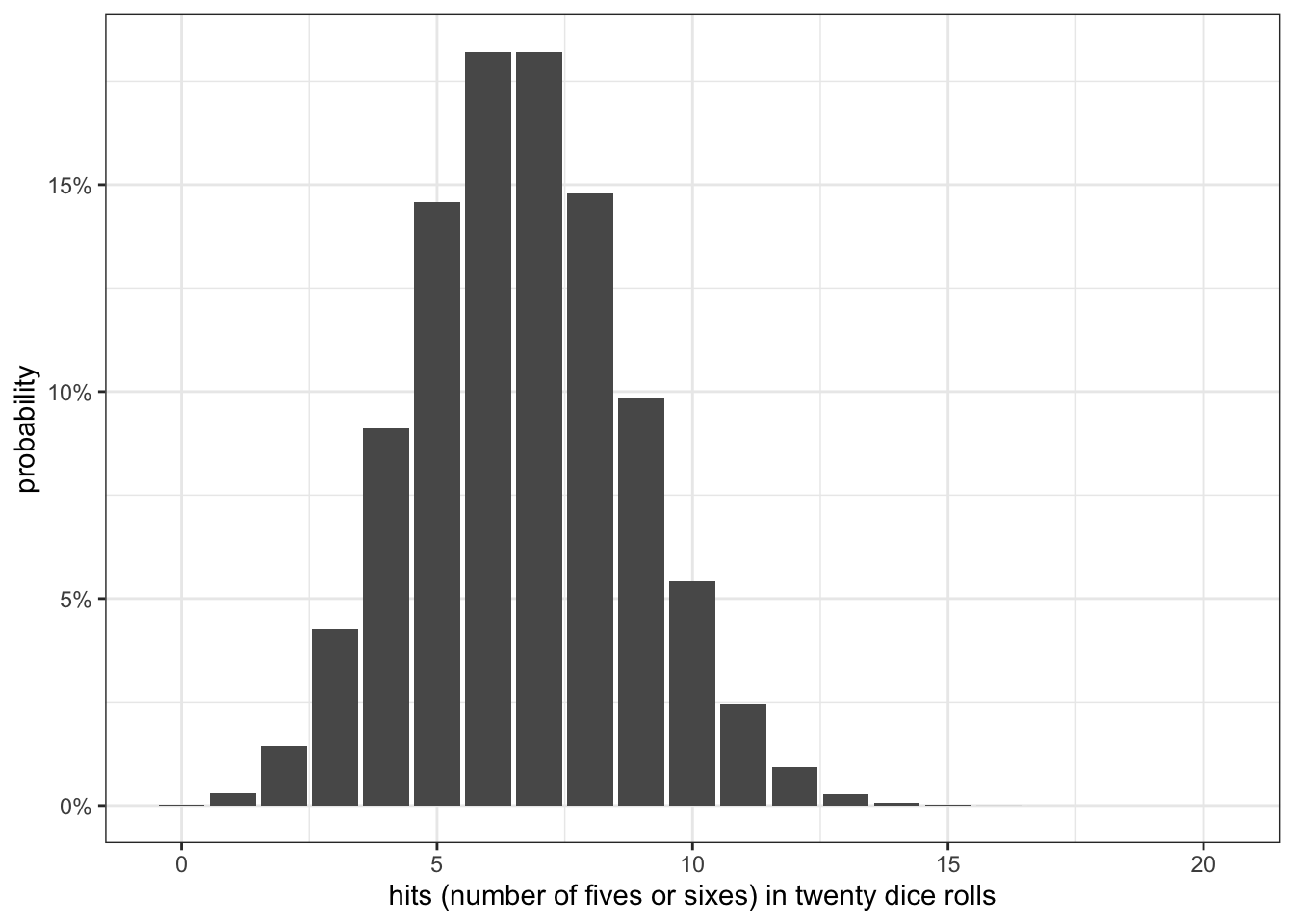
n <-20k <-0:np <-1/3prob <-choose(n,k)*p^k*(1-p)^(n-k)ggplot(tibble(k,prob), aes(x=k, y=prob))+geom_col()+scale_y_continuous(labels=scales::percent)+labs(x="hits (number of fives or sixes) in twenty dice rolls",y="probability")+theme_bw()
Figure 7.2: Probabilities of the number of hits (rolling a five or six) in a twenty dice pool
What would happen if we had a dice pool of twenty dice? Figure 7.2 shows the results. Of course, the most likely number of successes is higher because we are rolling more dice. The shape is also starting to look more like a normal distribution. This is not a coincidence. As \(n\) increases the shape of the binomial distribution will look more and more like a normal distribution.
Expected value and variance
The expected value of a random variable given by \(E(X)\) is the same as the mean of its probability distribution. In the case of the binomial distribution, the expected value is:
\[E(X)=np\]
If you think about it for a second, this value is completely intuitive. The expected number of successes is equal the probability of a success on any given trial multiplied by the number of trials.
We can also calculate the variance of the random variable \(V(X)\). For the binomial distribution, this is given by:
\[V(X)=np(1-p)\]
This formula has an important implication. First, the variance depends on the underlying probability of success. Second, for a given \(n\), this probability will be maximized at a certain value of \(p\). To see what value of \(p\) that is, lets go ahead and calculate the variance for our example with \(n=5\) for every possible \(p\) at 0.01 intervals, as shown in Figure 7.3.
p <-seq(from=0.001,to=0.999, by=.001)v <-5*p*(1-p)ggplot(data.frame(p,v), aes(x=p, y=sqrt(v)))+geom_line()+labs(x="probability of success",y="standard deviation in number of successes for n=5")+theme_bw()
Figure 7.3: Standard deviation for binomial distribution with five trials by different probabilities of success
The variance will always be at its greatest when the probability of success is 50%. As you get closer to probabilities of 0% or 100%, you will get less variance because most trials will be failures or successes, respectively.
The Bernoulli distribution
The Bernoulli distribution is a special case of the binomial distribution with just a single trial \((n=1)\). Alternatively, a binomial distribution can be thought of as the sum of \(n\) independent Bernoulli distributions. The Bernoulli distribution is particularly important for our purposes because each observation in our data typicallly only has one trial. The expected value of the bernoulli distribution is simply \(p\) and the variance is \(p(1-p)\).
The binomial distribution as a data-generating process
Let us now return to the Titanic example and consider the process that generated our actual data. In our actual data we only have a record of “successes” (i.e. survival) and “failures” (i.e. deaths). However, underlying this data, we can imagine that each passenger had their own very personal (and stressful) Bernoulli trial. Each passenger had some underlying probability of surviving the Titanic. We can refer to that underlying probability as \(p_i\). Importantly, it is subset by \(i\) because we imagine that probability was different for each passenger. Given that \(p_i\), each passenger was then given one bernoulli trial and the result was either survival or death.
Although survival and death is what we observe, what we actually want to know about is \(p_i\). Furthermore, we would like to know how \(p_i\) was affected by other characteristics of the passenger such as gender, passenger class, age, and fare paid. In the next section, we will make our first attempt at estimating these \(p_i\) values in a model.
Linear Probability Model
In the previous section, I said that you cannot fit a linear model by OLS regression if the dependent variable is categorical. This is mostly true, but not exactly true. I can brute-force an OLS regression model by turning a dichotomous dependent variable into numeric values of 0 (for failure) and 1 (for success). In R, I can do this by turning my dependent variable into a boolean statement. Lets try it with a model that predicts survival on the Titanic by fare paid.
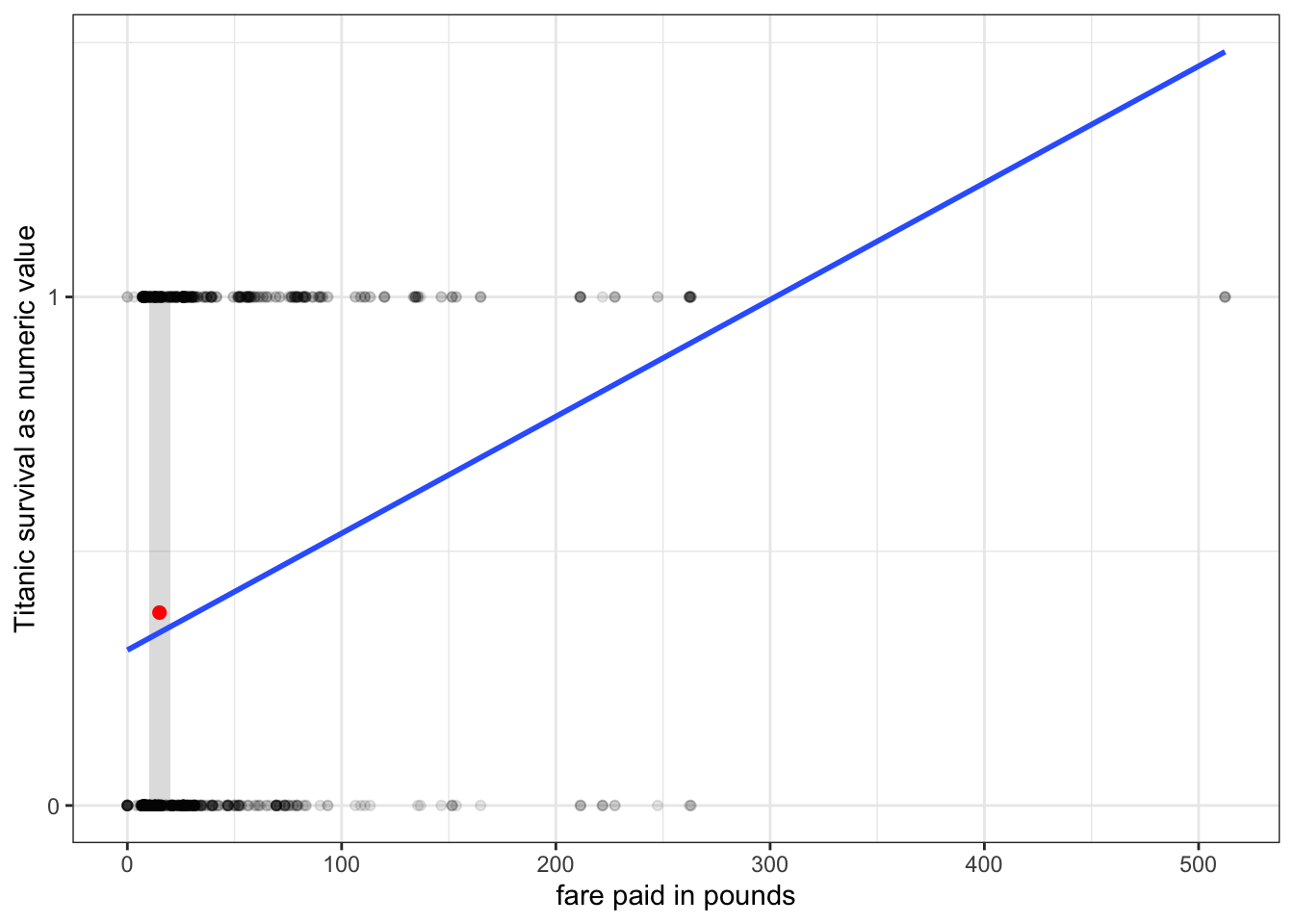
I now have a model that works, but what do the results mean? One way we can try to understand this model is by visualizing it on a scatterplot, as shown in Figure 7.4.
ggplot(titanic, aes(x=fare, y=as.numeric(survival=="Survived")))+geom_point(alpha=0.1)+geom_smooth(method="lm", se=FALSE)+scale_y_continuous(breaks =c(0,1), labels=c("0","1"))+labs(x="fare paid in pounds", y="Titanic survival as numeric value")+theme_bw()
Figure 7.4: Scatterplot of fare paid by survival on the Titanic with linear probability model fit. Points are shown with semi-transparency to address overplotting.
All of the points fall on two horizontal lines at \(y=0\) (deaths) and \(y=1\) (survivors). We can sort of see the positive relationship in that the deaths are more tightly clustered around low values of fare, while the survivors are more spread out. The blue line plots the OLS regression line I just calculated above.
If we were to take all the passengers at any interval, we could calculate the proportion who survived by simply taking the means of the zeros and ones for the survival variable. Lets try that for all passengers who paid between ten and twenty pounds:
So about 37.9% of the passengers paying between 10 and 20 pounds survived. Figure Figure 7.5 below shows this point graphically. You can see that it falls pretty close to the best-fitting line. This best-fitting line is estimating the same exact thing: the predicted proportion of survivors at a given value of fare.
Figure 7.5: Scatterplot of fare paid by survival on the Titanic with linear probability model fit. Red dot shows proportion of surviving passengers within the grey band.
This blue line is giving us the linear probability model. Formally, the linear probability model in this case gives us:
\[\hat{p}_i=0.3056+0.0023(fare_i)\]
The outcome, \(\hat{p}_i\) is the predicted probability of survival for the \(i\)th passenger. When fare paid is zero, we expect that probability to be 0.3056 of 30.56%. The model predicts that each additional pound of fare paid is associated with a 0.23 percentage point increase in the probability of survival.
At first glance, this model seems to give us exactly what we said we wanted from the last section – the predicted probability of survival for each passenger. However, it turns out there are two significant problems with the linear probability model that make it a less than ideal model.
Heteroscedasticity
The first problem is one we have seen before – heteroscedasticity. However, we will now see it in a new form. From the previous section we know that the variance of the actual survival outcome for a passenger should be given by:
\[p_i(1-p_i)\]
The problem here is that the variance of the outcome is itself a function of the value of \(p_i\) and \(p_i\) in our model will be different for each passenger. So, we have unequal variance in the residuals of our outcome and violate the assumption of identical distributions. Each passenger is reaching into their own very personal Bernoulli distribution to decide whether they live or die.
This problem is theoretically correctable, via the iteratively reweighted least squares approach that we used in Chapter 6. In this case, we need to apply weights to our results that are the inverse of the variance for each observation. In this case, the weight for each observation should be:
\[w_i=\frac{1}{\hat{p}_i(1-\hat{p}_i)}\]
Where \(\hat{p}_i\) is the estimated probability from our initial model. We can then iterate through models until our estimates stop changing. Lets try it out using our initial model from above as the starting point.
Error in lm.wfit(x, y, w, offset = offset, singular.ok = singular.ok, : missing or negative weights not allowed
It looks like something went wrong. The problem is that some of the values for \(\hat{p}_i\) are greater than one. You can look at the line in Figure 7.4 to confirm this issue. That causes problems in our approach because it makes some of the estimated weights negative. There is no particularly good approach to solving this problem. We could eliminate observations where \(\hat{p}_i>1\) or we could truncate those values to some value like 0.99, but if we choose 0.999 rather than 0.99, we will get different results. The fundamental issue is that we are running into the second problem with linear probability models detailed below – they can give you nonsense values for predicted probabilities outside the range of zero to one.
One solution to this problem if we still want to fit this model and deal with heteroscedastictity is to apply robust standard errors as we saw in the last module:
t test of coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.30555135 0.01525316 20.0320 < 2.2e-16 ***
fare 0.00229654 0.00025975 8.8414 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
This approach should give us correct standard errors. However, as is often the case with robust standard errors, we are getting correct standard errors for a bad model because we have not been able to address the much more important problem.
Nonsense values
By definition, the linear probability model fits probabilities via a straight line. The thing about straight lines is they just keep going up and up (or down and down) at a constant slope with no upper or lower limits on the values that they can take. However, a probability does have a very clear theoretical upper and lower bounds. Probabilities cannot be below zero or above one. You cannot have a -20% or 150% chance of surviving the Titanic.
In some cases, you may by happenstance get a line that fits within the theoretical range for the scope of your independent variable. However, there is no guarantee of this. Figure 7.6 below clearly shows that we get predicted probabilities above one within the scope of the data for our linear probability model of survival on the Titanic by passenger class.
Figure 7.6: Scatterplot of fare paid by survival on the Titanic with linear probability model fit. Points are shown with semi-transparency to address overplotting. Nonsense values above one and below zero are shaded in red.
While we can fix heteroscedasticity, there is no fix for this problem within the framework of the linear probability model. The linear probability model is not a very good model because it does not respect the underlying data generation process.
Logit transformation to the rescue
In order to resolve this problem, we need some kind of transformation of the \(p_i\) values that will cause them to be contained within the interval from zero to one. It turns out that the transformation we are looking for is the logit transformation.
The logit transformation converts a probability into the log-odds. Formally,
\[logit(p)=log(\frac{p}{1-p})\]
There are really two parts to this transformation. First, we convert from probabilities to odds by taking \(p/(1-p)\). We have seen odds before in this course, in the section on two-way tables. There we learned how to calculate the odds ratio. The odds is the ratio of the expected number of successes to failures. So, if \(p=0.75\), we expect that three out of every four trials will produce successes, on average. In terms of the odds, we expect three successes for every one failure. To convert:
Why do we convert from probabilities to odds? The advantage of the odds is that it has no upper limit. As the probability gets closer and closer to onem, the odds will approach infinity, with no finite limit. Therefore, any non-negative number for the odds can be converted back into a probability that will give sensible values between zero and one. I can convert back to a probability by:
\[p=\frac{O}{1+O}\]
So, for the case of \(O=3\) above:
\[p=\frac{3}{1+3}=\frac{3}{4}=0.75\]
Lets choose a really high odds like \(O=100,000\). If we convert back to a probability:
We get a very high probability, but its still less than one.
This partially helps us with our problems. If we were to look at a linear relationship between the odds of success and our independent variables we would get sensible probabilities no matter how high the predicted odds. However, it only partially helps us because it would still be possible to get negative odds from such a linear model which would be nonsensical.
The second step of logging the odds will get us all the way there. If I log a value below one, I will get a negative value and that logged value will approach negative infinity as the original value approaches zero. So a log-odds can always be converted back to a probability that will lie between zero and one.
To convert from a log-odds \(g\) to a probability, I take:
\[p=\frac{e^g}{1+e^g}\]
The value \(e^g\) converts from log-odds to odds and then I just use the formula for converting from an odds to a probability.
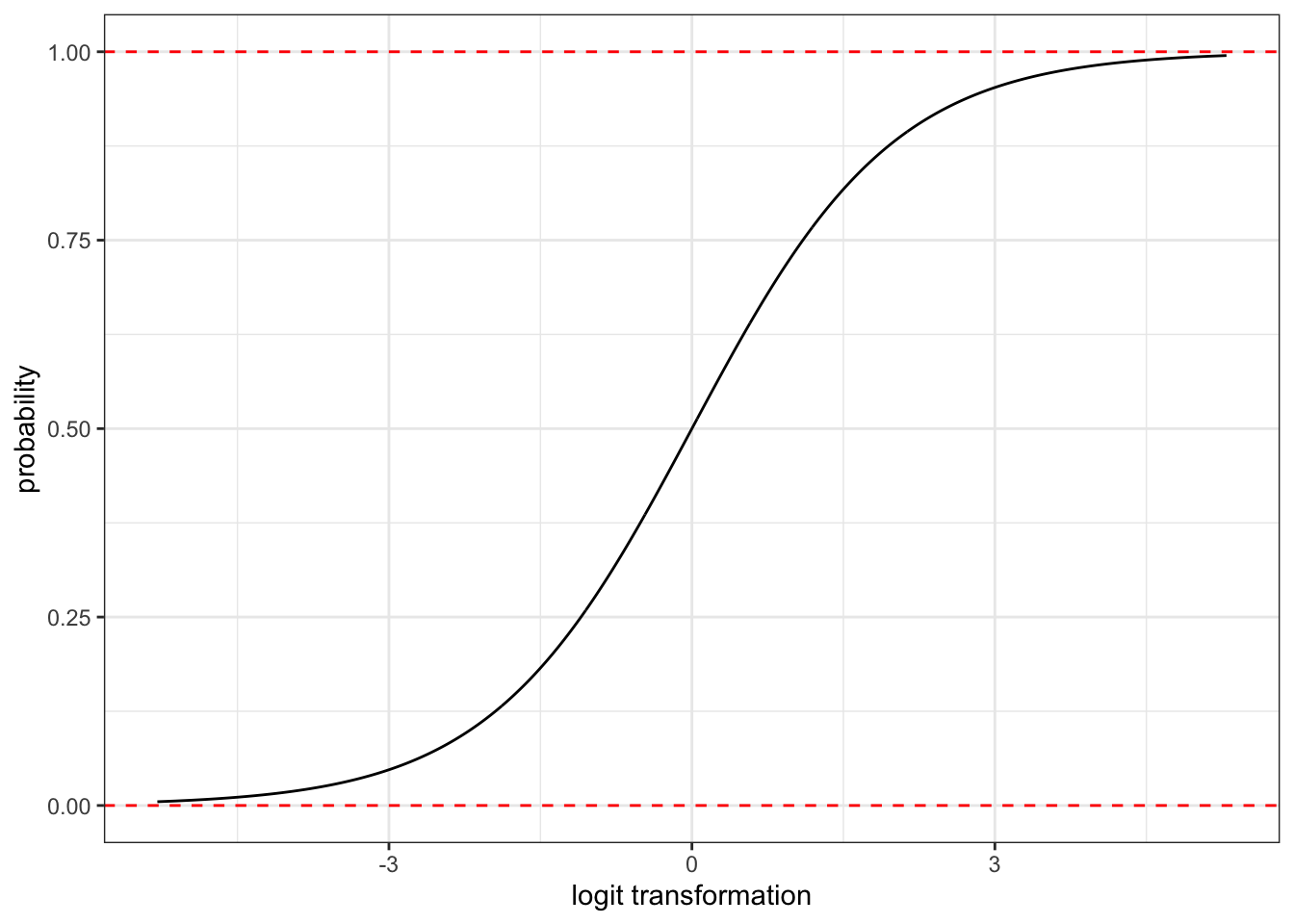
In essence the log-odds, or logit, transformation stretches out my probabilities across the entire number line. Figure 7.7 shows the relationship between probabilities and the logit value for probabilities between 0.5% to 99.5%:
Figure 7.7: The relationship between probability and the logit transformation
The “S” curve shown here is often called the logistic curve. There are a couple of things to note about this curve:
The curve approaches but never crosses the horizontal lines for \(p=0\) and \(p=1\). Thats because all finite logit values will produce probabilities within the correct theoretical range.
A probability of 50% corresponds to a logit of zero. Logit values below zero indicate probabilities less than 50% and logit values above zero indicate probabilities greater than 50%.
So, it seems like we now have a potential solution to our problem with the linear probability model. If we were to transform our dependent variable from predicting probabilities to predicting log-odds, we could then get predicted log-odds for each passenger on the Titanic. When converted back to probabilities, we would be ensured that our predicted probabilities never strayed beyond zero and one.
That all sounds great, except there is an important catch.
Error in lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...): NA/NaN/Inf in 'y'
We cannot actually apply this transformation directly to our dependent variable, as we have done in the past. Why not? The problem is that we want to apply this transformation directly to \(p_i\) but we don’t have \(p_i\). We only have the actual recorded outcome as either a zero (died) or a one (survived). But there are no proper finite values of the logit at exactly zero and one. So, this approach will not work using OLS regression techniques. In order to get what we want, we need to move to a new model estimation technique – the Generalized Linear Model.
Generalized Linear Model
Generalized linear models (GLM) will allow us to extend the basic idea of our linear model to incorporate more diverse outcomes and to specify more directly the data generating process behind our data.
To better understand what GLMs do, I want to return to a particular set-up of the linear model. In this set-up, there are two equations. The first equation partitions the value of an actual outcome \((y_i)\) into the part accounted for by our model \((\hat{y}_i)\) and the random residual “leftover” bits \((\epsilon_i)\):
\[y_i=\hat{y}_i+\epsilon_i\]
We then have a second equation that details how the structural model part \((\hat{y}_i)\) is specified by a linear function of the independent variables:
We should have a good sense of the second equation by now as its the basic linear model set-up. I want to focus more on the first equation right now. Its important to remember that the error terms \((\epsilon_i)\) are randomly drawn from some distribution. Its not important what that distribution is so long as all of the \(\epsilon_i\) are drawn from the same distribution independently. However, for the purposes of illustration lets assume that the \(\epsilon_i\) are being drawn from a normal distribution. We can then describe that distribution mathematically as:
\[\epsilon_i \sim N(0, \sigma)\]
The \(\sim\) sign means “distributed as.” In this case, our error terms are distributed as a normal distribution that is centered on zero and has some standard deviation \(\sigma\). It doesn’t really matter what that \(\sigma\) is for our purposes here.
Think about this from a data-generating perspective. To get an actual value of \(y\) for the \(i\)th observation:
We feed all of that observation’s values for \(x\) into our linear function which gives us a predicted value of \(y\), \(\hat{y}_i\). This is only the structural part. All observations with the same values of \(x\) will get the same \(\hat{y}_i\) because we have not added the random bit.
Reach into our normal distribution and pick out a residual that we add onto the end of our predicted value to get the actual value. This residual adjusts for all the random factors not accounted for in our model that might cause variation between observations with the exact same predicted value.
One way of thinking about the second part is that instead of reaching into a normal distribution centered on zero for the residual, we are reaching into a normal distribution centered on \(\hat{y}_i\) because all we are going to do is add the constant value of \(\hat{y}_i\) to whatever we pull out of that distribution. Therefore, we can actually re-write the first equation parsing \(y\) into the structural and stochastic components as:
\[y_i \sim N(\hat{y}_i, \sigma)\]
We can now have all the pieces to reformulate this linear model in the framework of the generalized linear model.
Generalized linear model framework
The generalized linear model requires two components: the error distribution and the link function.
The error distribution specifies how the outcome that we actually measure in our data is distributed. In this case, the error distribution is given by:
\[y_i \sim N(\hat{y}_i, \sigma)\]
Therefore, the error distribution is normal. The normal distribution is also sometimes called the **gaussian* distribution and that is how we will specify it in R below.
The link function specifies how the linear function of the independent variables is related to the key parameter of the error distribution. In this case the key parameter of the error distribution is \(\hat{y}_i\) and our linear function is related directly to that parameter:
In this case, the link function is somewhat invisible because there is not really a link function at all. We are simply relating the linear function of the independent variables directly to the key parameter of the error distribution. In practice this si called the identity link.
So within the generalized linear model framework, we can express our traditional linear model as using a gaussian error distribution and an identity link. Lets go ahead and try that out. The command glm in R will estimate a generalized linear model. We will talk later in this section about how that estimation works, but for now I just want to focus on the results.
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.9969128 0.07221383 55.34830 0.000000e+00
nsports 0.5044705 0.04282271 11.78044 1.462129e-31
To specify the error distribution and link function, I used the family argument in the glm command. Lets compare this result to the traditional lm command that is estimated via OLS regression:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.9969128 0.07221383 55.34830 0.000000e+00
nsports 0.5044705 0.04282271 11.78044 1.462129e-31
The results are identical. Keep in mind that these two commands used completely different estimation strategies. We know that OLS regression minimizes the sum of squared residuals. The GLM uses a technique called maximum likelihood estimation that we will learn about later in this section. However, the key point is that they both produced the same estimate. When we specify the data-generating process as a guassian error distribution with an identity link, we are estimating a traditional linear model. The maximum likelihood estimate for this model is the one that minimizes the sum of squared residuals.
At this point, this new framework and estimation approach hasn’t really done much for us. The lm command will work fine and we also don’t need to make the assumption that our residual terms are normally distributed for OLS regression models to be valid. So why set up this more complex framework? The answer is that by changin the error distribution and link function, we can accomodate a broad set of models that are cannot be estimated well by OLS regression techniques. Most of those models involve categorical variables. The most common model is the logit model (also called the logistic regression model) that can be used for dichotomous outcomes.
A GLM for dichotomous outcomes
In order to help us understand the logit model better, I want to start this in reverse. We will play god and actually generate the data. Then we can use the model to help recover the process we used to generate the data.
For this example, I want to stick with the theme of ocean liner disasters, but I want to create my own disaster. To do that, we are going to use the fictional example of the Good Ship Lollipop. The Good Ship Lollipop has a large number of 10,000 passengers. We know two things about these passengers: their gender and the amount they paid in fare. To create the passengers of the Good Ship Lollipop I am going to use some handy functions in R for producing random outcomes:
gender fare
Length:10000 Min. : 0.0124
Class :character 1st Qu.: 28.8997
Mode :character Median : 69.5907
Mean : 100.2615
3rd Qu.: 138.8270
Max. :1204.5128
The data looks pretty reasonable. Unfortunately, the Good Ship Lollipop is going to hit an iceberg and sink on its first voyage because the crew were too busy singing and drinking spiked Shirley Temples to keep an eye out. Some passengers will survive this sinking and some will not. Since I am playing god, the first thing I need to do is figure out the underlying \(p_i\) probability of survival for each passenger.
I want \(p_i\) to be a function of gender and fare paid. However, I know that its not safe or sensible to make it a direct linear function because I am end up with nonsensical values of \(p_i\). If I instead make the log-odds (or logit) of survival be a linear function of gender and fare paid, then I will be assured that when the log-odds are converted to probabilities, all the probabilities will fall between zero and one. So I set up my model:
The numbers I put in here aren’t particular important and I could vary them if I wanted to change how they related to survival. Right now, I am saying that men were less likely to survive and fare was positively associated with survival. The baseline log-odds of survival for a man who paid no fare is 0.05 which works out to a probability of 0.512 or 51.2%.
Lets go ahead and feed this equation into my data to get predicted log-odds. We can then convert from those log-odds to probabilities:
The probs vector gives us the probability of survival for every passenger. In order to complete this process I now need to have every passenger make their Bernoulli trial to see if they survive the disaster. I can do this easily in R by using the rbinom function:
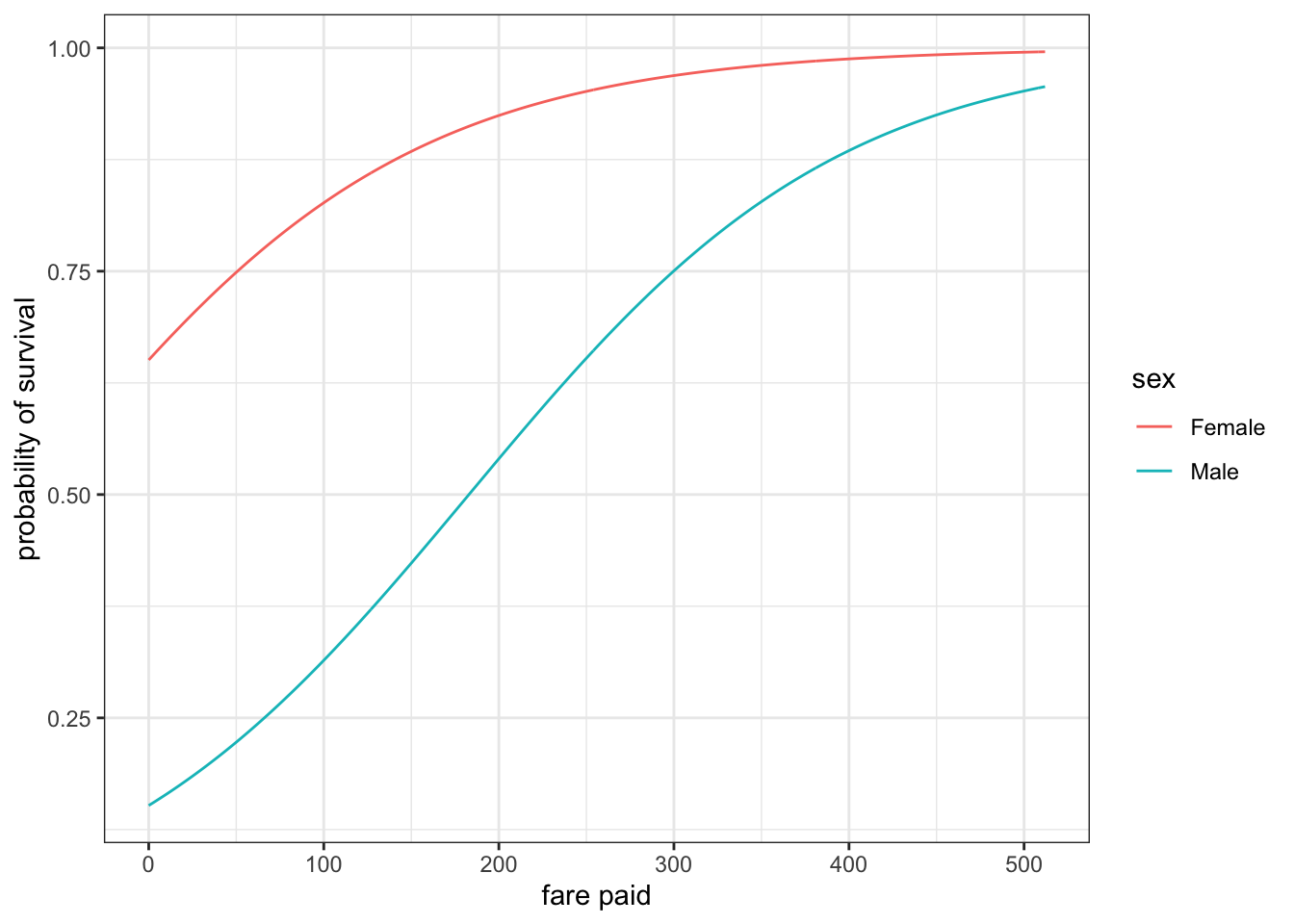
ggplot(good_ship, aes(x=fare, color=gender))+geom_point(aes(y=survived), alpha=0.2)+geom_line(aes(y=probs))+labs(x="fare paid", y="probability of survival")+theme_bw()
Figure 7.8: Life and death on the Good Ship Lollipop. The lines show the underlying probabilities of survival by gender and survival. The dots show actual outcomes after drawing a bernoulli trial for each passenger.
Figure 7.8 visualizes how this all played out. We can see that women were more likely to survive. This difference in survival shrank as fare paid increased because both groups started to approach the 100% probability threshold. We can also see from the dots that more women ended up in the survivor group as we would expect and that people were more likely to survive at higher fares paid. What we are seeing in Figure 7.8 is the data-generating process. The lines give us the underlying probabilities and the dots show us the realization of those probabilities into the ones and zeros we actually would have in the data.
Can we reverse this data-generating process to recover the values I used to construct the probabilities? We can do so using a GLM approach. In this case we know the error distribution and link function.
The error distribution tells us how our dependent variable is distributed. In this case, we either have a 1 (survived) or a 0 (died). Each of these values was produced by a binomial distribution with \(n=1\) and a probability equal to \(p_i\). So:
\[y_i \sim binom(1, p_i)\]
The key parameter in this error distribution is \(p_i\). The link function should tell us how we relate \(p_i\) to the linear function of the independent variables of gender and fare. In this case, the relationship is not direct. We related the linear function of the independent variables to the log-odds or logit of the probability of survival:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.099102969 0.0369032368 2.685482 7.242533e-03
genderMale -0.426517519 0.0416495575 -10.240625 1.303907e-24
fare 0.004761864 0.0002519497 18.900058 1.139270e-79
It worked! Note that my coefficient estimates are very close to the actual values I used when playing god. They differ slightly because there is some inherent randomness in choosing survivors and deaths by the binomial distribution.
We now have a framework for a model that predicts dichotomous outcomes. This is called the logit model or logistic regression model. In practice, it is one specification of the generalized linear model.
However, we still need to understand two things. First, how are those values actually estimated in the generalized linear model? We will take that up below. Second, how do we interpret those results? We will take that up with a more thorough discussion of the logit model in the next section.
Maximum likelihood estimation
The technique that the generalized linear model uses to estimate parameters (i.e. intercept and slopes) is called maximum likelihood estimation. This technique is different than the technique we learned for OLS regression model which sought to minimize the sum of squared residuals, although it turns out that OLS regression technique is the maximum likelihood estimate for a simple linear model. However, we now have a more complex model that does not even have residuals in the sense that we have been using up to this point.
The basic principle of maximum likelihood estimation (MLE) is fairly straightforward: We choose the parameters that maximize the likelihood of observing the data that we actually have. More formally, the process of maximum likelihood estimation operates as follows:
We have some data-generating process that produces a set of observed outcomes. In the case of the Titanic of the Good Ship Lollipop, these outcomes are the vectors of zero and one that indicate death or survival. This data-generating process is governed by some unknown parameters. In our case, those unknown parameters are the intercept and slopes of the linear function in our link function. In general, we call the set of unknown parameters \(\theta\) as a shorthand.
Based on the data-generating process, we can construct a likelihood function, \(L(\theta)\) that determines the probability of observing the data that we actually observe, assuming some \(\theta\). The important thing to note about the likelihood function is that its a function of the unknown parameters \(\theta\), not the actual data, which are known.
We determine what values of \(\theta\) would produce the maximum possible value in the likelihood function \(L(\theta)\). These are the maximum likelihood estimates. As usual to find maximums of functions, we need to use calculus. In practice, we typically log the likelihood function to get the log-likelihood function and find the maximum for that function which will give us the same result. We prefer the log-likelihood function because it makes multiplicative functions additive, which simplifies the math.
This is all very abstract, so lets take a simple example. Lets say I flip a coin 50 times and observe 20 heads. What is my maximum likelihood estimate of \(p\), the probability that we get a head on a single coin toss?
Now, you may be saying to yourself, isn’t the probability of a head on a coin toss 50%? It is true that we have strong prior beliefs that this should be so. However, the principle of maximum likelihood estimation is to produce estimates purely driven by the data at hand, not prior beliefs. So we are going to act naively and estimate \(p\) via MLE.
What is our data-generating process. We know that this is a basic binomial process. However, we are making some changes here from how we usually conceptualize this binomial process. Before, we have always known \(p\) and \(n\) (number of trials) and then considered the probability of getting \(k\) successes. Now, we know \(n\) and \(k\) and want to figure out \(p\). The good news is that our likelihood function is familiar:
\[L(p)={50 \choose 20}p^{20}(1-p)^{30}\]
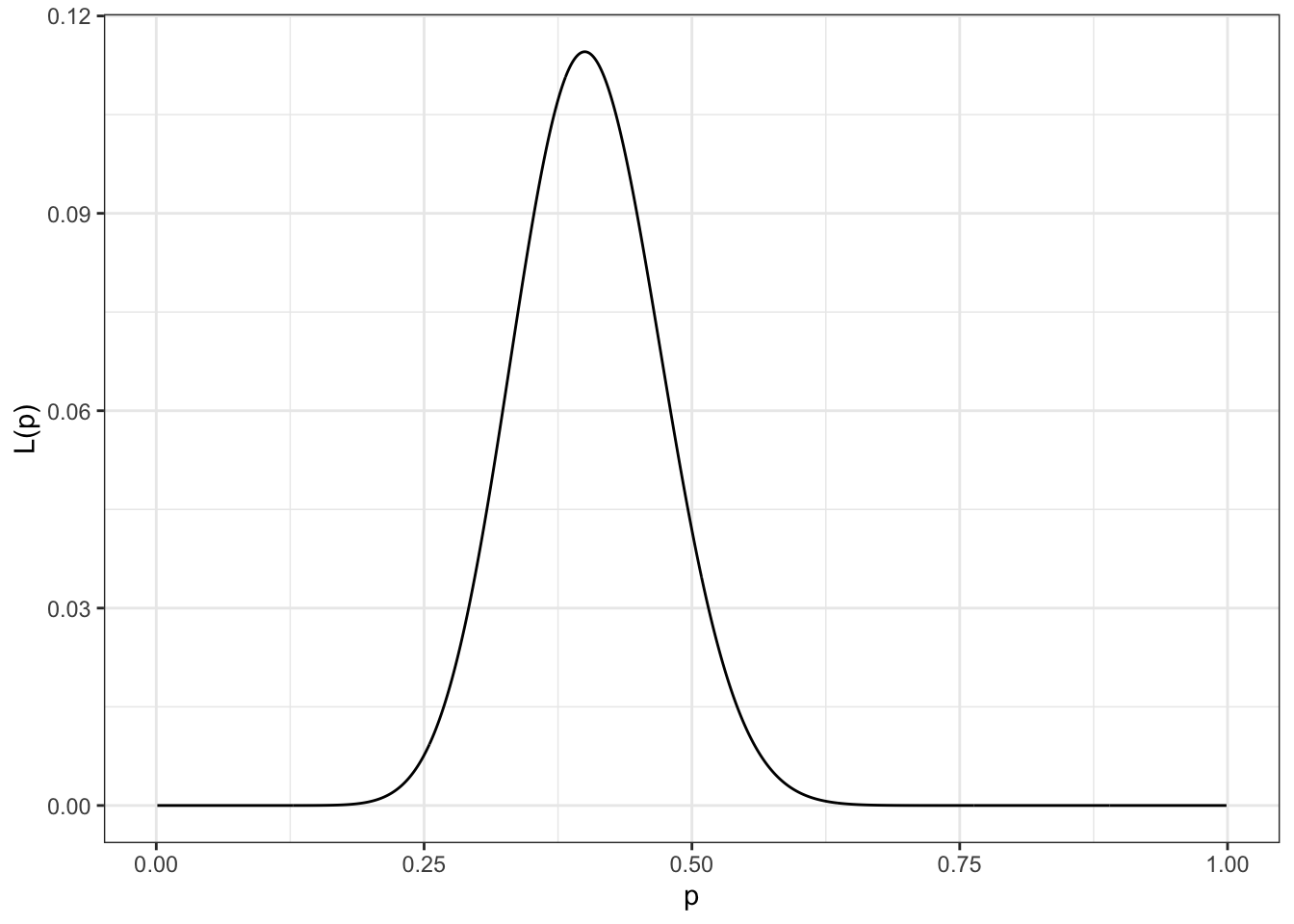
The likelihood function is just the binomial formula. Except now it is a function of \(p\) with the values for \(n\) and \(k\) filled in. Remember that a likelihood function gives us the probability of getting the data that we actually have. This function will give us the probability of getting 20 heads in 50 coin tosses for a given value of \(p\). We just need to figure out which value of \(p\) will actually give us the maximum possible value for \(L(p)\). We can do this by brute force by just using R to try every possible value of \(p\) from 0.001 to 0.999, as I have done in Figure 7.9.
p <-seq(from=.001, to=.999, by=.001)likelihood <-choose(50,20)*p^20*(1-p)^30ggplot(data.frame(p, likelihood), aes(x=p, y=likelihood))+geom_line()+labs(y="L(p)")+theme_bw()
Figure 7.9: Likelihood function for p from binomial process with 50 trials and 20 successes. It is clearly maximized at p=0.4.
Figure 7.9 shows the likelihood function for \(p\) calculated by hand. It is clear that the reasonable range of values of \(p\) are between about 0.25 and 0.55 and \(L(p)\) is maximized at \(p=0.4\). This should not be surprising. If we have a binomial process with 50 trials and 20 successes, then our best guess for the probability of a success is \(20/50=0.4\).
Now lets try to derive the \(p\) that maximized \(L(p)\) more formally. To find the maximum of a function we need to take the derivative of that function and solve for zero1. As I noted earlier, it is usually easier to take the derivative of a log-likelihood function, so lets first log our likelihood function:
Now, we just need to take the derivative of this function with respect to \(p\). If you know calculus, this is a mildly complex and enjoyable calculation that you can try out, but for others I will tell you mathemagically, the derivative comes out to:
In general, if you replace 20 and 50 with \(n\) and \(k\), then this result will give you the MLE solution of \(p=k/n\).
MLE for GLMs
The previous example is fairly simple and we are able to get a closed-form solution that is satisfying and straightforward. Maximum likelihood estimation for GLMs is not so easy.
Lets consider our case for the logit model. Each observation gets a bernoulli trial to determine success where the outcome of 0 or 1 is recorded at \(y_i\). Therefore, the likelihood \(L_i\) for a single observation is given by:
\[L_i=p_i^{y_i}(1-p_i)^{1-y_i}\]
This formula may look complicated, but its fairly straightforward. If the passenger survived \((y_i=1)\), then this formula just simplifies to \(p_i\),the probability of survival for that passenger. If the person did not survive \((y_i=0)\), then this formula just simplifies to \((1-p_i)\), the probabiility of not surviving for that passenger.
As usual, lets take the log of that likelihood to get the log-likelihood:
\[\log L_i=y_i\log(p_i)+(1-y_i) \log (1-p_i)\]
To get the log-likelihood of all observations, we just need to add up these log-likelihoods. Why do we add them? On the original scale of likelihoods, we would multiply them together, so on the log-scale we add them.
Now, the only problem we have at the moment is that our goal is to maximize the slopes and intercept of our linear model but we don’t have those in the formulat the moment. However, we can add that by remembering that we were predicting the log-odds of success as a linear function of the independent variables:
\[log(\frac{p_i}{1-p_i})=\mathbf{x_i'\beta}\]
I am writing the linear function in matrix notation here \((\mathbf{x_i'\beta})\) for brevity. We can convert this back to \(p\) by using the formula for converting from log-odds to probabilities:
We now have the full log-likelihood function for a logit model. To figure out \(\beta\) we just have the rather difficult task of finding the \(\beta\) values that maximize this function.
Finding the MLE for this log-likelihood function is no easy task and there are no closed-form solutions as there were for the simple binomial process case. We need to use iterative estimation procedures to estimate the best values for \(\beta\).
Several algorithms have been developed for finding MLE for this case and for other forms of the GLMs. The technique that I will show you below uses a version of iteratively-reweighted least squares (IRLS). You will never typically have to do this as the glm command will do all of the heavy-lifting here, but its worthwhile to have some familiarity with how glm is doing what it does. I will show you below how this procedure works using the case of the Titanic where we predict survival by fare paid. Lets first set up our outcome vector of zeros and ones:
y <-as.vector(as.numeric(titanic$survival=="Survived"))head(y)
[1] 1 1 0 0 0 1
Beause we will also be using matrix notation, I am also going to set up my design matrix of independent variables, taking consideration to add a column of ones for my intercept.
X <-as.matrix(cbind(rep(1,nrow(titanic)), titanic[,"fare"]))head(X)
The basic IRLS procedure is to estimate via an iterative procedure. To get the process started we first fit the null model as our logit model. The null model just assumes that every observation had an equal probability of survival.
mean(y)
[1] 0.381971
#convert to log-oddslodds <-log(mean(y)/(1-mean(y)))lodds
[1] -0.4811908
Based on the proportion of survivors, the log-odds of survival as a whole was -0.4811908. So my null model is:
\[\log(\frac{p_i}{1-p_i})=-0.4811908\]
Lets set this up as my initial \(\beta\) vector:
beta <-c(lodds, 0)
I can matrix-multiply this vector by my design matrix to get predicted log-odds which I can convert to \(p\). At this point, they all should give me the same value.
I can also use that p vector to calculate my log-likelihood for the current model:
logL <-sum(y*log(p)+(1-y)*log(1-p))logL
[1] -870.5122
Now I want to iterate this process and improve my estimation. At each iteration \(t\) of the process, I estimate the best-fitting \(\beta\) vector for \(t+1\) by the following formula:
This formula is somewhat similar to the OLS regression formula we saw in Chapter 6. We can see the design matrix \(\mathbf{X}\) of independent variables. We also have a \(\mathbf{X}\) weighting matrix to consider. You will also notice a \(z\) vector where we would usually have a \(y\) vector.
The weighting matrix only has non-zero values along the diagonal. These values are given by:
\[w_i=\hat{p}_i(1-\hat{p}_i)\]
Where \(hat{p}_i\) is estimated probability of success for observation \(i\) from the current iteration of the model. I can estimate this weighting matrix from my initial model as follows:
W <-matrix(0, nrow(X), nrow(X))diag(W) <- p*(1-p)
The \(z\) vector accounts for the transformation of the dependent variable and is estimated as:
You can see that I now have a non-zero slope for fare paid and a less negative log-likelihood which means a higher overall likelihood. I can keep iterating this procedure until my \(\beta\) values stop moving around. Lets try a total of six iterations from the top:
#initial null modellodds <-log(mean(y)/(1-mean(y)))beta <-c(lodds, 0) pred_lodds <- X%*%betap <-exp(pred_lodds)/(1+exp(pred_lodds))logL <-sum(y*log(p)+(1-y)*log(1-p))beta.prev <- betafor(i in1:6) { w <- p*(1-p) z <- pred_lodds + (y-p)/w W <-matrix(0, nrow(X), nrow(X))diag(W) <- w beta <-solve(t(X)%*%W%*%X)%*%(t(X)%*%W%*%z) beta.prev <-cbind(beta.prev, beta) pred_lodds <- X%*%beta p <-exp(pred_lodds)/(1+exp(pred_lodds)) logL <-c(logL, sum(y*log(p)+(1-y)*log(1-p)))}beta.prev
By the sixth iteration, my intercept and slope values have stopped changing down to the eighth decimal place and the log-likelihood has also stabilized. Lets compare our results to the glm command to see how they compare:
We get the exact same values from the glm command.
Logit Model
Now that we have developed the logic behind generalized linear models and the maximum likelihood estimation procedure, we can focus more concretely on the GLM we used to predict survival in the previous section. This GLM is the logit model (also called the logistic regression model) and it can be used to predict dichotomous outcomes. Formally:
These two functions define the error distribution and link function, respectively. Each outcome \(y_i\) (success or failure) is the result of a binomial distribution with a single trial and an estimated \(\hat{p}_i\) probability of success for the \(i\)th observation. The linear function of the independent variables is related to the log-odds of success, which is a transformation of those \(\hat{p}_i\). We use MLE to then estimate the \(\beta\) values by selecting the \(\beta\) values that produce \(\hat{p}_i\) that maximize the likelihood of actually observing the success and failures \((y_i)\) that we actually have.
Interpreting results
Because of the transformation in the link function, we have to be careful about interpreting the results from our model. We have already seen something like this before in the previous module in which we log-transformed the dependent variable. The effect here is similiar, but is also compounded by the use of odds rather than probabilities in the link function. In short, we have to consider two things:
We are modeling differences or effects on the odds of success rather than on the probability of success. Because of the non-linear connection between these two concepts, it is no easy matter to go between them. We will take this more up below in a discussion of the “marginal effects” from logit models.
Because of the natural log in the logit transformation, the actual model we care about is multiplicative rather than additive. In other words, our ultimate interpretations will be about relative change (e.g. 7% lower, twice as large) on the odds of success.
A simple example
Lets try out a simple example. I want to use my new logit model framework to predict survival on the Titanic by gender.
But what do the values for the intercept and the slope really mean? These are literally given me predicted changes in the log odds of survival, but log odds is not very intuitive. Lets use our usual trick of exponentiating both sides to convert the left-hand side to and odds.
As you can see, this equation became a multiplicative equation rather than an additive equation, just as it did for log-transformed quantitative variables in the previous module. In this case, we can figure out what these numbers mean very easily by plugging in values for \(female_i\) for our two cases. For men, \(female_i=0\), so:
So the exponential of the intercept value \((e^{-1.444}=0.236)\) gives us the odds of survival for men. This value is often called the baseline odds and represents the odds of success for an observation when all values of the independent variable are zero.
We could work out the final number here, but this formulation is more important because it gives us the odds ratio of 11.3. This is the value we multiply the baseline odds by in order to get the odds for women. In this case, we can see that women had odds of surviving the Titanic that were 11.3 times higher than men’s odds. In general the exponential of the slopes gives us an odds ratio, although interpreting it correctly depends on whether you have a categorical or quantitative independent variable.
Before discussing the quantitative case, lets revisit a method we already knew for calculating this odds ratio. We can do this by a two-way table.
table(titanic$sex, titanic$survival)
Survived Died
Female 339 127
Male 161 682
The odds of survival for men are given by the number of survivals over the number of deaths:
161/682
[1] 0.2360704
You can see that this number matches the baseline odds we just calculated from the logit model. We can also calculate the odds ratio by taking the cross-product of the table:
339*682/(161*127)
[1] 11.30718
The odds ratio between men and women is the same as what we just estimated from the logit model. The logit model and the two-way table both agree on the relevant odds and odds ratios. So why use the logit model? The logit model will allow us to estimate much more complex models by including quantitative variables, controlling for other variables, adding interaction terms, non-linear effects, and all of the other fun techniques we have been developing for the right-hand side of a linear function. Before turning to a more complex model, lets look at how to interpret logit models with a quantitative independent variable.
Interpreting results with quantitative independent variables
Lets return to the example of predicting survival by fare paid:
Again we have a multiplicative model. To see how we can interpret this multiplicative effect, lets consider the predicted odds for three passengers who respectivly paid 0,1, and 2 pound(s) in fare:
Each time we increase a pound in fare, we multiply the odds we had before by 1.012. In other words, the odds increase by 1.2% for every one pount increase in fare. So, for a quantitative variable, we can also talk about the percentage or multiplicative change in the odds, but this time for a one unit increase in \(x\) rather than comparing a one category to a reference category.
Also note that because our slope of 0.012 was small, the exponential of this value followed the approximation of \(e^x\approx1+x\), and was simply 1.012. Therefore, in this case, we could have just looked directly at the log odds ratio of 0.012 and concluded that every one pound increase in fare paid is associated with a 1.2% increase in the odds of survival.
Graphing predicted probabilities
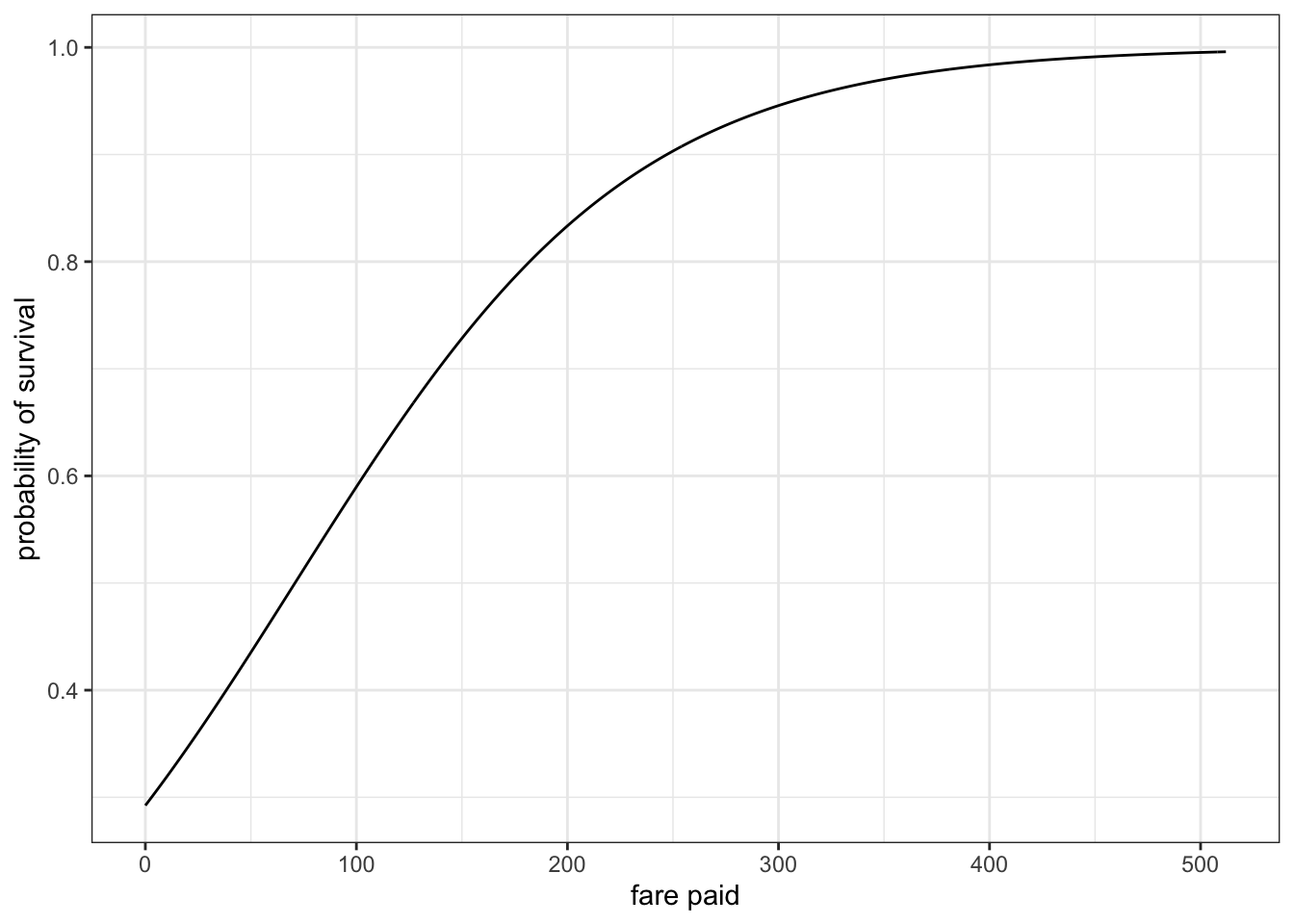
We can look at how fare changes the predicted probability of survival by using the predict command. In this case, we will feed in a fake dataset of passengers paying every fare between 0 and 512 (the maximum actual value) in one unit increments. We just have to remember that the predicted values from predict will be log-odds which need to be converted to probabilities.
Figure 7.10: Predicted probability of survival by fare, based on logit model. The result bends as it approaches one and will not cross that value.
We could also plot a more complicated example for a model that looks at both gender and fare. The trick here is we can use a handy function called expand.grid to set up our prediction dataset. The expand.grid function will create a data.frame that includes an observation for every possible combination of the variables that you feed in.
The baseline odds of frequent smoking for a 10th grade girl who earned a C average and is not a member of honor society is about 0.37. So roughly, I expect to see about 3 non-frequent smokers for every frequent smokers among this group.
Holding constant gender, grade in school, and honor society membership, each letter grade increase in GPA is associated with nearly a halving (50.1% decline) in the odds of frequent smoking.
The grade effects are a little harder to directly interpret because of the squared term applied in a multiplicative fashion. The basic trend is that increases in grade are associated with fairly large increases in the odds of frequent smoking. The negative effect on the squared term suggests a slightly diminishing effect at higher grade levels, but this is not statistically significant, so we are probably better off estimating a model without the squared term.
To see how this complex age effect works, its probably easiest to calculate odds ratios at each of the grades from 7th through 12th:
We can see that the biggest odds ratio increase is from 7th to 8th grade at 49.7% and the smallest estimated odds ratio increase is from 11th to 12th at 23.6%. Although the magnitudes vary in size, the risk of smoking increases substantially in size with increases in grade at all grade levels.
The effects of gender and honor society are also somewhat more complex to interpret because of the interaction term. The main effects give us the effect when the other variable is held at the reference. So, among students who are not in honor society, and controlling for grade and GPA, boys have 13.7% lower odds \((100*(1-0.863))\) of frequently smoking than girls. Among girls, honor society membership reduces the odds of smoking by about 49.8% \((100*(1-0.502))\).
To interpret the interaction term, lets go ahead and calculate the honor society effect for boys:
exp(-0.68964864+0.79507849)
[1] 1.111188
Among boys, those in honor society have 11% higher odds of smoking frequently than those not in honor society. So we see a very different effect of honor society here by gender.
Notice that I could have gotten this same value by multiplying the exponentiated values of the main effect and interaction term:
0.5017523*2.2146148
[1] 1.111188
Marginal effects
The coefficients of the logit model give the marginal effect on the log-odds of success, but we rarely want this value. Exponentiated coefficients will give the odds ratio of success for a one unit increase in \(x\) for all values of \(x\). Often times, however, what people really want when they refer to the “marginal effects” in a logit model is the marginal effect of \(x\) on the probability.
Before proceeding with such a calculation, it is worth pausing for thought here. We converted to the odds scale because of the fundamental problem of probabilities being bound between zero and one. Because of this, the effect of an independent variable must be smaller when we are close to this bounds. This has the unfortunate effect of mixing up “intecept effects” with relationships between variables when we focus on probabilities. An “intercept effect” is something that affects all the cases and raises or lowers their probability of success. For example, the Costa Concordia sinking off the coast of Italy had a much lower death rate than the Titanic for a variety of reasons (e.g. modern safeguards, temperature of the water, proximity to shore). Thes factors raised everyone’s probability of surviving much higher, such that differences between passengers by gender had to be smaller. However, we should not conclude from this that the smaller difference between men and women’s survival was driven by anything to do with gender itself, but rather to the ceiling effect of approaching 100% survival. The odds and odds ratio gets us away from this problem, by removing the “intercept effect” from our estimates of the effect of a given independent variable on the outcome. We can directly compare the odds of survival by gender between the Titanic and Costa Concordia, but not the probabilities.
Nonetheless, recently many academics have become convinced that the only proper way to report parameters from a logit model is to convert them to marginal effects on the probabilities. I am not a fan of this Logit Panic, but I do think its worthwhile for you to know how to do this procedure. For more information on why I think concerns about the logit model are misplaced, see this excellent article.
The first problem with calculating marginal effects on the probabilities is the question of where you want to calculate them. Because the relationship between the log-odds and probabilities is a curve (the logic curve, to be precise), the marginal effects vary depending on the predicted probability of success, \(\hat{p}_i\) for a given \(x\) or vector of \(X\) in the case of multiple independent variables.
Lets take the example of the effect of fare paid on surviving the Titanic. Figure 7.12 below shows three different marginal effects at fares of 50, 200, and 500 pounds. These marginal effects are given by the tangent line to the curve at each of these values of fare. The tangent line is the line that just “kisses” the curve at each value of fare, and gives us the slope of the curve at that exact moment. We can see that the steepness of the curve changes. As fare increases, the probability of surviving also increases and thus the marginal effect of fare decreases because we are approaching one.
Figure 7.12
To calculate the marginal effect of a given variable \(k\) with a coefficient of \(\beta_k\), you just need to use the formula:
\[\hat{p}(1-\hat{p})\beta_k\]
where \(\hat{p}\) is the predicted probability of success for a given set of values for the independent variables. We can calculate that value by using our formula to get predicted probabilities for a given vector \(X\) of values:
For example, lets calculate the marginal effect of paying an additional pound of fare when we are currently paying fifty pounds. Our model of survival by fare paid is given by:
So, an increase in fare paid from fifty to fifty-one pounds is associated with an increase in the probability of survival of 0.29%.
We can also do this with models that have more than one variable, but now we will have to estimate a \(\hat{p}\) for values of more than one variable. One approach in these cases is to estimate the marginal effects on the probability when at the mean for all independent variables. Lets try it out for a model that uses both fare and age to predict survival.
model <-glm((survival=="Survived")~fare+age, data=titanic,family=binomial(logit))#get predicted probabilty at mean fare and agedf <-tibble(fare=mean(titanic$fare), age=mean(titanic$age))lodds <-predict(model, df)p <-exp(lodds)/(1+exp(lodds))#get marginal effectsp*(1-p)*coef(model)[c("fare","age")]
fare age
0.003181225 -0.003548695
So, holding age at the mean, a one pound increase in fare from the mean is associated with an increase in the the probability of survival of 0.32%. Holding fare at the mean, a one year increase in age is associated with a decrease in the probability of survival of 0.35%. Coincidentally, the marginal effects of fare and age at the mean are about the same but in opposite directions.
For categorical variables, the marginal effect on the probability is simply given by the difference in probability between the indicated and reference category. Lets add gender to our model and estimate its marginal effect on the probability.
Men had a 52% lower probability of surviving the Titanic than women, holding fare and age at the mean values.
How do we calculate the marginal effects for fare and age in this last model. Gender is categorical and therefore we can’t just take the mean. Or can we? You may have noticed that I created a new variable called female coded directly as a 0/1 dummy variable. The mean of this variable is the proportion female on the Titanic. Although it would seem odd to do so, I can use this mean to get a predicted value for the probability mathematically. The result just tells me the expected log-odds/probabilities among a set of passengers where the proportion female equals that for the whole dataset. I can then use this approach to calculate the marginal effects for my quantitative variables.
If you don’t want to go through the hard work of calculating these marginal effects by hand, you are in luck. The mfx library has a command called logitmfx. This command will run a logit model and report back the marginal effects on the probability.
Call:
logitmfx(formula = survival ~ fare + age + sex, data = titanic)
Marginal Effects:
dF/dx Std. Err. z P>|z|
fare -0.00226367 0.00039441 -5.7394 9.501e-09 ***
age 0.00167113 0.00110885 1.5071 0.1318
sexMale 0.51694014 0.02589350 19.9641 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
dF/dx is for discrete change for the following variables:
[1] "sexMale"
Notice that this function also reports back inferential statistics in addition to the marginal effects themselves.
The probit link
The logit link is the most common link used for generalized linear models with dichotomous outcomes. However, another link option is the probit link. Formally the probit link is the inverse of the cumulative normal distribution, but its ok if that doesn’t make a lot of sense to you.
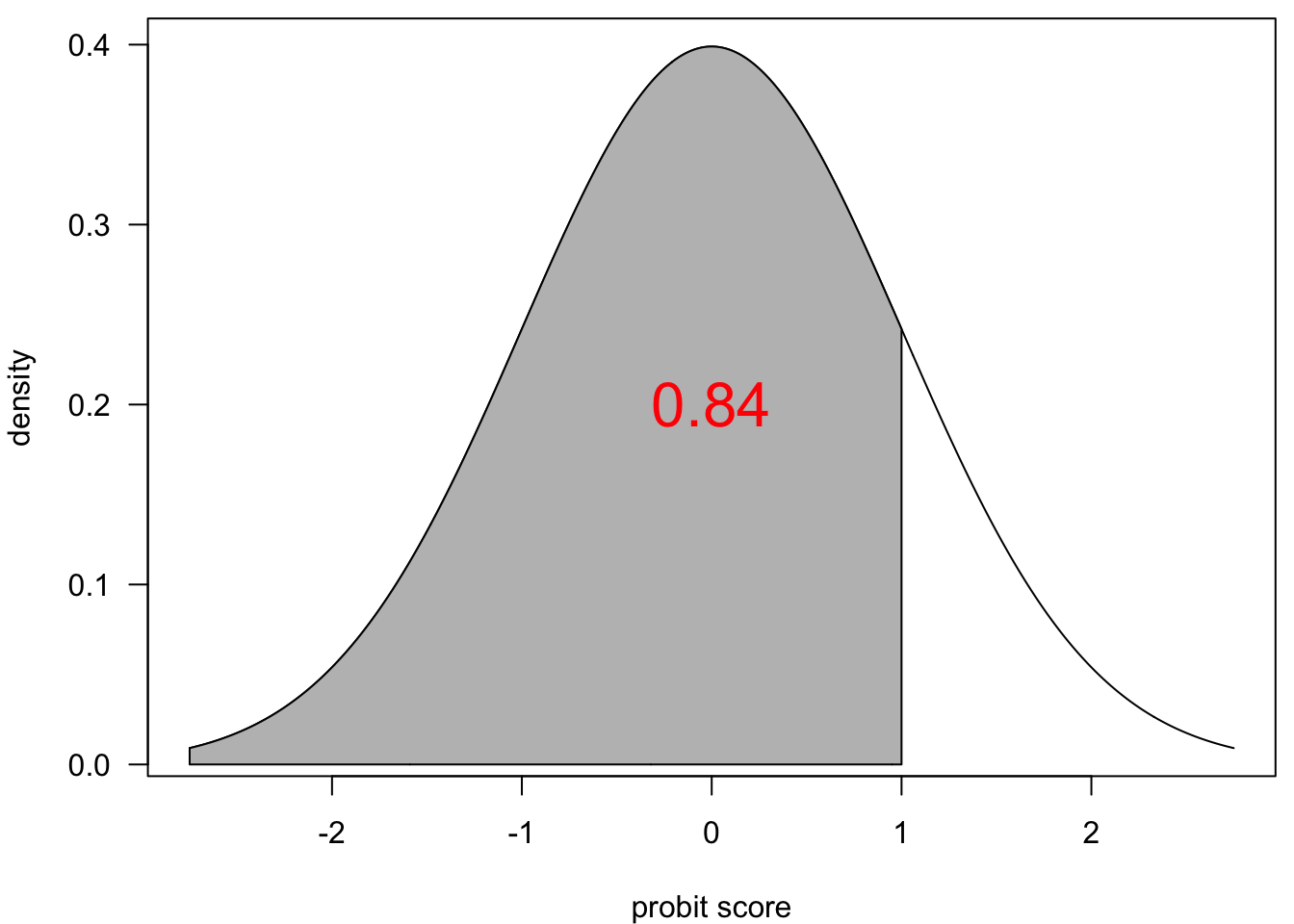
Just imagine that you had a standard normal distribution with a mean of zero and standard deviation of one. The cumulative normal distribution gives us the density (proportion of the area) of that standard normal distribution for a given value. So imagine you put in a value of one. A value of one would correspond to being one standard deviation above the mean.
Standard normal distribution with area to the right of one standard deviation above the mean shaded.
?fig-cum-normal shows what that area is in the shaded region. 84% of the area of a standard normal distribution is below that one standard deviation mark. The inverse cumulative normal distribution just reverses which number we are asking about. Instead of feeding in “+1 SD” to get 0.84, I feed in 0.84 to get “+1 SD.” The idea is that we can represent any given probability as an abstract score on a continuous distribution that ranges from negative infinity to infinity. So, just like the logit transformation. the probit transformation stretches the probability across the full number line.
To use a probit model, just replace the logit link with the probit link in your glm command:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.53844140 0.045234388 -11.90336 1.136704e-32
fare 0.00720295 0.000908147 7.93148 2.165503e-15
The downside of the probit model is that the results are much more difficult to interpret. The direction of the effect can be determined, but the magnitude is often difficult to gauge. For this reason, the logit model is usually preferred.
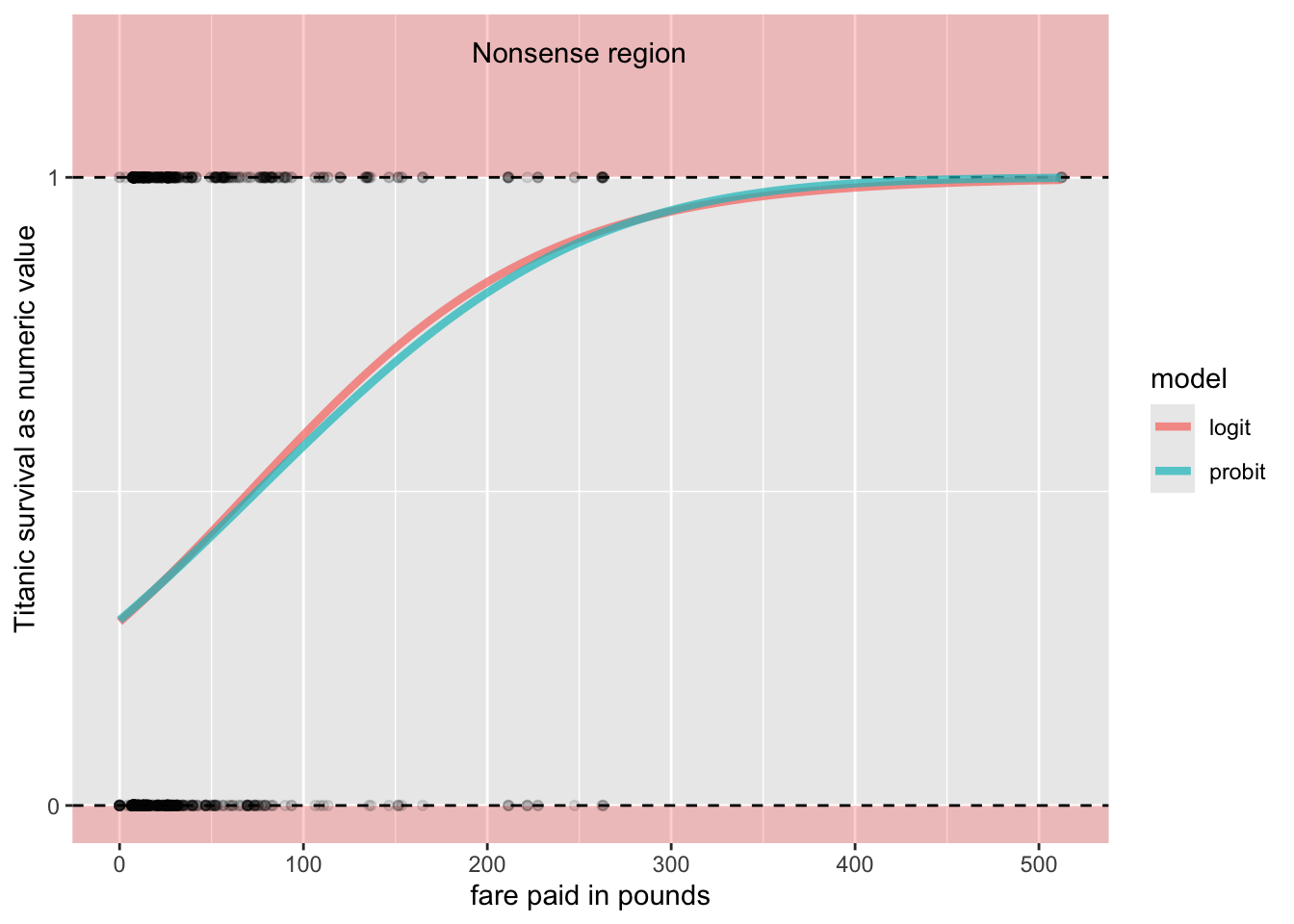
The two link functions usually produce very similar results. Figure 7.13 compares the probability fit of the two types of models when predicting survival by fare paired. The results are nearly identical.
Figure 7.13: Predicted probabilities of survival on the Titanic by fare paid using a logit and a probit model
Assessing model fit
For a linear model, we typically assess goodness of fit by the \(R^2\) value for the model which gives us the proportion of the variance in the dependent variable that can be accounted for by the independent variables. However, once we move to a logit model, we no longer have an \(R^2\) value. This is because we are not actually estimating \(\hat{y}_i\), the predicted values of \(y_i\), which we use to calculate residuals and \(R^2\). Rather, we are calculating the underlying log-odds and probabilities of success for the data-generating process.
However, the maximum likelihood estimation (MLE) procedure used for GLMs gives us another measure of goodness of fit. Remember that MLE selects the model parameters that maximize the likelihood of observing the data that we actually observe. The likelihood associated with the best-fitting model is itself a measure of goodness of fit. However, we don’t typically use the likelihood itself but rather a derived measure called deviance. The deviance \((G^2)\) of a generalized linear model is given by:
\[G^2=-2 (logL)\]
Where \(logL\) is the log-likelihood of the model. We basically multiply this value by -2. Why we choose -2 is a bit complicated and we won’t delve into it here, besides saying that it allows for some other mathematical properties that just work.
Remember that the log-likelihood is the log of a probability. Because probabilities are between zero and one, the log of the likelihood will always be a negative number. The more negative the log-likelihood, the closer the likelihood to zero and therefore the poorer the fit of the best-fitting model. When we multiply this value by a negative value to get the deviance, the directionality reverses. A high deviance indicates worse fit – think of it like a golf score. Lower numbers are better, which intuitively makes sense of something called “deviance.”
The glm object in R gives us the deviance directly:
model_fare$deviance
[1] 1654.783
The value of the deviance by itself is usually not that interesting. What we are interested in is the value of this deviance in comparison to other models of the same outcome. The implicit comparison is always to the null model. Luckily, the glm object also gives us the deviance of this null model, so we can directly compare them.
model_fare$null.deviance
[1] 1741.024
model_fare$null.deviance-model_fare$deviance
[1] 86.24176
Our model using fare as a predictor of survival reduced the deviance from the null model (where everyone had the same probability of survival) by 86.2. Is that a good number? There are several approaches to gauging the magnitude of that value.
Likelihood Ratio Test
The Likelihood Ratio Test (LRT) is analagous to the F-test for linear models. It can be used to compare any two nested models where the null hypothesis is that all additional independent variables in the more complex model have a slope of zero.
The LRT is tested by using the reduction in deviance in the more complex model as the test statistic. If the null hypothesis is true, then this test statistic should come from a chi-squared distribution with degrees of freedom equal to the number of additional variables in the more complex model. The chi-squared distribution has a somewhat similar shape to an F-distribution and won’t delve into the details here. We simply look for the area in the right tail of this chi-squared distribution to calculate the p-value. The pchisq function in R will give us this left-tail area and so we can just subtract this from one to get the right-tail area. Lets try it out by running an LRT of our fare model versus the null model.
1-pchisq(86.2,1)
[1] 0
The reduction in deviance is so large that our p-value is very close to zero. We reject the null hypothesis in this case.
You can also use the anova command to do an LRT but you have to remember to specify test="LRT" as an argument:
Just like the F-test, we can compare any two nested models using the LRT. Lets try a model with passenger class and then one with passenger class and fare.
The model with fare added reduces deviance by an additional 10.9 over the model just with passenger class. The p-value for this improvement is not quite as good as the last one, but is still very low and we would surely reject the null hypothesis.
Keep in mind, that the LRT has all the same drawbacks as the F-test. It is based on the logic of hypothesis testing and therefore it will prefer more complex models in larger samples.
Pseudo-\(R^2\)
Pseudo-\(R^2\), also called McFadden’s D provides a very simple measure of goodness of fit. It simply calculates the reduction in deviance as a proportion of the null deviance. To calulcate pseudo-\(R^2\):
\(D=\frac{G^2_0-G^2}{G^2}\)$
where \(G^2_0\) is the deviance of the null model. Although not the same as \(R^2\), the idea is quite similar. The null deviance is as large as your deviance can get, so to ask how much we reduced the deviance, it makes intuitive sense to place it on a scale of how much deviance there was that could be accounted for in the first place.
To calculate the reduction in deviance for our fare model:
Using fare to predict the likelihood of survival reduces the deviance from the null model by about 5 percent.
BIC for GLMs
We can also calculate a BIC for generalized linear models just as we did for linear models. Because we have no \(R^2\) value the calculatioon is different, but the interpretations are the same.
To calculate BIC for any two models:
\[BIC=(G^2_2-G^2_1)+(p_2-p_1)\log n\]
Where \(G^2_1\) and \(G^2_2\) are the deviance for model 1 and model 2, respectively, and \(p_1\) and \(p_2\) are the number of independent variables in models 1 and 2, respectively. The resulting BIC gives you the relative preference for model 2 over model 1. A negative BIC means that model 2 is preferred to model 1 and the more negative this value, the stronger the preference.
Lets use this formula to compare the BIC of our passenger class model to the passenger class and fare model:
Because the BIC is negative but less than -5, we have a moderate preference for the more complex model. Note that we could have gotten this same result by just using the BIC command on each model (which takes BIC relative to the saturated model) and subtracting them:
BIC(model_complex)-BIC(model_pclass)
[1] -3.739362
Using the formula from above, we can also construct a BIC’ value where we compare the model to the null model. We just need to plug in values for the null model as model 1:
\[BIC'=(G^2-G^2_0)+(p)\log n\]
Unfortunately, R does not have a built-in function for this calculation, but we can create a custom function pretty easily:
BIC.null.glm <-function(model) { n <-length(model$resid) p <-length(model$coef)-1return((model$deviance-model$null.deviance)+p*log(n))}BIC.null.glm(model_fare)
[1] -79.06474
BIC.null.glm(model_pclass)
[1] -113.4114
BIC.null.glm(model_complex)
[1] -117.1508
By comparing the results, we can see that we strongly prefer all three models to the null model. Of the three models, we get the most negative BIC’ for the model that includes both fare and passenger class. Note that the difference between the passenger class model and the complex model is the same as above with the built-in BIC function.
Separation can occur in logit models when the categories of the dependent variable separate an independent variable or combination of independent variables into segments. The easiest case to understand would be a two-way table in which all the values of category 1 and category 2 on one variable are identical to the values of another set of categories on another variable. Lets imagine a simple example of a yes/no question by gender of respondent for a simple case of six respondents:
y <-factor(c("yes","yes","yes","no","no","no"))x <-factor(c("female","female","female","male","male","male"))table(x,y)
y
x no yes
female 0 3
male 3 0
In this table, gender perfectly predicts a yes or no response. This is called perfect separation. If we try to predict yes/no by gender with a logit model, we will get some odd results:
Call:
glm(formula = y ~ x, family = binomial)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 24.57 75639.11 0 1
xmale -49.13 106969.82 0 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 8.3178e+00 on 5 degrees of freedom
Residual deviance: 2.5720e-10 on 4 degrees of freedom
AIC: 4
Number of Fisher Scoring iterations: 23
Notice that the model reports values although it spits out a warning. However, the numbers in the coefficient table are all strange. My coefficient sizes are huge (-49 log-odds ratio), my standard errors are astronomical and my p-value is so close to 1 that it reports as 1. These are all signs of separation. The MLE solution does not exist for this data because the slope on male should be negative infinity!
Complete separation can also happen for a quantitative independent variable.
x <-c(20,21,22,23,24,25)model_sep <-glm(y~x, family=binomial)
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
summary(model_sep)
Call:
glm(formula = y ~ x, family = binomial)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 1062.76 2594089.60 0 1
x -47.23 115264.41 0 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 8.3178e+00 on 5 degrees of freedom
Residual deviance: 2.2152e-10 on 4 degrees of freedom
AIC: 4
Number of Fisher Scoring iterations: 25
I get a similar problem here because the quantitative variable can be perfectly separated by the dependent variable at age 22. All observations less than or equal to 22 say yes and all those above 22 say no.
Perfect separation is a fairly rare occurrence, except in very small datasets. A more common occurrence is quasi-complete separation in which the dependent variable partially separates the independent variable. Lets continue with our example from before:
y <-factor(c("yes","yes","yes","no","no","no"))x <-factor(c("female","female","female","male","female","male"))table(x,y)
y
x no yes
female 1 3
male 2 0
In this case, gender does not perfectly predict the yes/no response. However, I get no cases of men who said yes. When you see cases of zero cells in your two-way table, it indicates that you have sparseness in the data and also quasi-complete separation. The effects of quasi-complete separation will be similar to complete separation.
Call:
glm(formula = y ~ x, family = binomial)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 1.099 1.155 0.951 0.341
xmale -20.665 7604.236 -0.003 0.998
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 8.3178 on 5 degrees of freedom
Residual deviance: 4.4987 on 4 degrees of freedom
AIC: 8.4987
Number of Fisher Scoring iterations: 18
The effects are not quite as exaggerated as for complete separation, but again I get enormous effect sizes with standard errors that are even larger, producing p-values close to one. If you see a result like this in your model, you have a problem of quasi-complete separation.
Separation causes problems for model estimation. One way to resolve the issue is to try collapsing categorical variables with lots of categories. If some of these categories are small, then they could lead to sparseness when added to the model. This is particularly true if you start adding interactions between categorical variables. By collapsing some categories you may be able to remove the problem of sparseness.
In cases where collapsing the variables is not an option, you can consider alernate estimation techniques. The most common is a penalized likelihood model. These models apply a penalty to the likelihood for very large coefficient sizes and can be used to pull extreme coefficients resulting from separation back closer to a reasonable value.
You can implement a penalized likelihood model in R using the logistf package. This package includes a function logistf that can be used to directly estimate a penalized likelihod logit model.
library(logistf)logistf(y~x)
logistf(formula = y ~ x)
Model fitted by Penalized ML
Confidence intervals and p-values by Profile Likelihood
Coefficients:
(Intercept) xmale
0.8472979 -2.4567358
Likelihood ratio test=2.278345 on 1 df, p=0.1311918, n=6
Models for Polytomous Outcomes
Technically we also need to show that the second derivative is negative at this value of \(p\), but we will skip that step here. You can try it as an exercise at home if you are so inclined↩︎